
Wszystkie treści na stronie ir.migra.pl chronione są prawami autorskimi. Więcej informacji znajdziesz tutaj.
Zapisy podstawy programowej 2024 realizowane w temacie:
III. Posługiwanie się komputerem, urządzeniami cyfrowymi i sieciami komputerowymi.
Zakres rozszerzony. Uczeń spełnia wymagania określone dla zakresu podstawowego, a ponadto:
1) dokonuje kompresji informacji, objaśnia różnice między kompresją stratną i bezstratną tekstów, obrazów, dźwięków, filmów;
Spis treści
- Na czym polega kompresja danych?
- Rodzaje kompresji
- Algorytmy kompresji stratnej
- Algorytmy kompresji bezstratnej
1. Na czym polega kompresja danych?
Kompresja (z łac. compressio – ściśnięcie) w różnych dziedzinach nauki oznacza zmniejszenie objętości (np. w fizyce – objętości cieczy, gazów). W informatyce kompresja odnosi się do zmniejszania objętości (wielkości) danych. Nie każde zmniejszenie objętości danych jest jednak kompresją.
Dane odtworzone nie muszą być dokładnie takie same jak oryginalne – pewne metody kompresji powodują usunięcie niektórych fragmentów danych.
Dla każdego zbioru danych istnieje minimalna objętość, do jakiej mogą zostać skompresowane. Oznacza to, że raz skompresowanych danych nie da się najczęściej ponownie skompresować.
Zastosowania kompresji danych są bardzo różnorodne. Bez kompresji nie istniałyby standardy JPEG, DVD, Blu-ray czy MP3. Kompresja pozwala także na efektywniejsze wykorzystywanie łączy telekomunikacyjnych (stosuje się ją np. w modemach).
Korzystamy z następujących wzorów:
lub
gdzie:
Rc, R’c – współczynniki kompresji,
Vk – objętość danych skompresowanych (w bajtach),
Vnk – objętość danych nieskompresowanych (w bajtach).
Wzór [1] pozwala nam obliczyć, jak bardzo dane zmniejszyły się w stosunku do oryginalnych, a wzór [2] – ile miejsca zaoszczędziliśmy.
Ze współczynnikiem kompresji wiąże się pojęcie przepływności (ang. bit rate, bitrate). Stosuje się je w przypadku strumienia danych, a więc ciągu danych przesyłanych w czasie rzeczywistym (np. filmów, muzyki). W takim przypadku musimy dysponować urządzeniem zdolnym do przesłania w czasie jednej sekundy określonej liczby bitów. Przesłanie danych będzie możliwe tylko wtedy, gdy zostaną one odpowiednio zmniejszone. Przepływność podajemy najczęściej w bitach (lub wielokrotnościach bitów) na sekundę, np. 128 Kb/s oznacza, że dane zmniejszono tak, by jedna sekunda filmu lub dźwięku zajmowała nie więcej niż 128 kilobitów.
2. Rodzaje kompresji
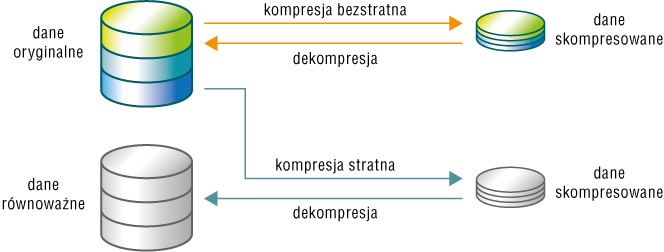
W przypadku kompresji bezstratnej dane odtworzone są identyczne (bit po bicie) z danymi pierwotnymi. Natomiast w przypadku kompresji stratnej dane odtworzone są podobne do danych pierwotnych i na ogół różnią się od nich w sposób trudny do wychwycenia.
Z oczywistych względów kompresja stratna nie może być wykorzystywana do każdego rodzaju danych. Zmiana choćby jednej litery w tekście może prowadzić do całkowitej zmiany jego sensu. Podobnie zmiana nawet jednego bitu w programie komputerowym może spowodować jego zupełnie inne działanie (program może np. wykonać odejmowanie zamiast dodawania). Z drugiej strony, prawdopodobnie nikt nie zauważy niewielkiej zmiany koloru kilku pikseli obrazu komputerowego. Zastosowanie odpowiedniego rodzaju kompresji jest więc wymuszone przez rodzaj danych, które zamierzamy skompresować (tabela 1.).

2.1. Algorytmy kompresji stratnej
Algorytmy kompresji stratnej bazują na niedoskonałościach ludzkich zmysłów. Nie dostrzegamy np. niewielkich zmian barw lub drobnych różnic w fakturze powierzchni na obrazie. Jeżeli w danym momencie brzmi jednocześnie wiele dźwięków, słyszymy tylko niektóre z nich, itd. Algorytmy kompresji stratnej usuwają informacje o tych elementach obrazu lub dźwięku, których nie jesteśmy w stanie dostrzec lub usłyszeć. Ponieważ takich informacji jest zaskakująco wiele, kompresja stratna jest bardzo efektywna.
Objętość pliku z obrazem lub dźwiękiem można zmniejszyć nawet dziesięciokrotnie bez zauważalnego dla obserwatora lub słuchacza pogorszenia jakości. Dopiero przy dalszym zmniejszaniu objętości różnice zaczynają być odczuwalne. Do utraty jakości może też prowadzić wielokrotne powtarzanie cyklu kompresji i dekompresji, np. kilkunastokrotne odczytanie i zapisanie obrazka w formacie JPEG.
2.2. Algorytmy kompresji bezstratnej
Algorytmy statystyczne
Algorytmy statystyczne operują na pojedynczych blokach danych (np. znakach tekstu lub fragmentach obrazu o określonej wielkości). Bazują one na właściwościach statystycznych tekstu, np. takiej, że znaki w tekście występują z różną częstością. W tekstach w języku polskim najczęściej występują samogłoski „a”, „e”, „i”, „o”, litery takie, jak „ź” czy „ń” pojawiają się rzadko, natomiast znaki takie, jak „&” czy „#” występują zupełnie sporadycznie.
Przykładem kodowania tekstu opartego na częstości występowania znaków w tekście jest alfabet Morse’a. Znaki tego alfabetu są kodowane za pomocą dwóch symboli: kropki i kreski. Twórca alfabetu (Samuel Morse) przyjął zasadę, że kod danej litery jest krótszy, jeśli dana litera występuje w tekście częściej. Na przykład kod litery B to: − • • •, a kod litery A, która występuje częściej niż B, to: • −. W alfabecie Morse’a nie rozróżnia się małych i wielkich liter.
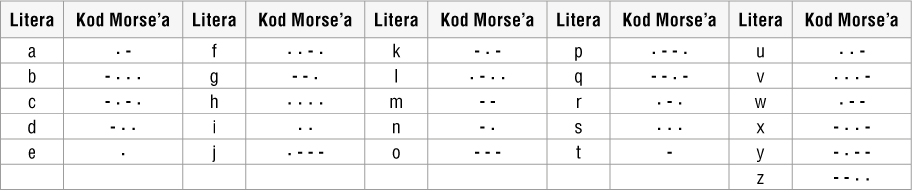
![]() Przykład 1. Alfabet Morse’a
Przykład 1. Alfabet Morse’a
Aby odczytać tekst zakodowany za pomocą alfabetu Morse’a, wystarczy zastąpić kolejne kody odpowiednimi literami.
W alfabecie Morse’a zapis: · ·/ – ·/· ·- ·/- – -/·- ·/- -/·-/-/- ·- -/- ·-/·- oznacza INFORMATYKA. Uwaga: Znakiem „/” oddzielamy kody liter, a znakiem „//” – wyrazy.
![]() Ćwiczenie 1. Odkodowujemy tekst
Ćwiczenie 1. Odkodowujemy tekst
Żeby dowiedzieć się, jaki tekst Samuel Morse zakodował w pierwszej depeszy nadanej w 1844 roku, odkoduj napis:
•− −/• • • • /•−/−//• • • • /•−/−/• • • •//− − •/− − −/− • •//• − −/• − •/− − −/• • −/ − − •/• • • •/−
![]() Ćwiczenie 2. Kodujemy tekst
Ćwiczenie 2. Kodujemy tekst
Zakoduj w alfabecie Morse’a swoje imię.
Algorytm kompresji statystycznej może działać na następującej zasadzie: do zapisania każdego znaku przy użyciu kodu ASCII potrzebujemy dokładnie 8 bitów. Jeżeli jednak do zapisu najczęściej używanych znaków wykorzystamy ciągi bitów o mniejszej długości (np. 2 lub 3 bity), zaoszczędzimy dużo miejsca. Oczywiście, aby każdy znak dało się jednoznacznie zidentyfikować, niektóre znaki trzeba będzie zapisać za pomocą więcej niż 8 bitów. Za pomocą tak długich ciągów można jednak zapisać znaki rzadko występujące, więc ostatecznie tego typu kompresja jest efektywna.
Algorytmy słownikowe
Algorytmy słownikowe operują na ciągach bitów o zmiennej długości (w szczególności na ciągach znaków). Patrząc np. na tekst zapisany w języku polskim, łatwo zauważyć, że pewne ciągi znaków często się powtarzają (np. w tym akapicie słowo „na” ze spacją pojawiło się już trzy razy, a słowo „np.” – dwa razy). Teoretycznie można więc utworzyć słownik zawierający wszystkie możliwe ciągi znaków, a następnie zamiast znaków tekstu posługiwać się numerami słów w słowniku. W praktyce tekst jest przeglądany od początku do końca i jeżeli algorytm natrafi na ciąg znaków, który pojawił się już wcześniej, zamiast całego tekstu zapisuje jedynie informację o miejscu, w którym wcześniej określony ciąg znaków się pojawił.
![]() Przykład 2. Stosowanie algorytmu słownikowego
Przykład 2. Stosowanie algorytmu słownikowego
Zdanie: The rain in Spain falls mainly on the plain. (44 bajty)
po skompresowaniu może mieć postać:
The rain<3, 3>Sp<9,4>falls m<11,3>ly on t<34,3>pl<15,3>. (32 bajty)
Zapis <x,y> (tzw. token) oznacza, że dana kombinacja znaków pojawiła się x znaków wcześniej i miała długość y znaków. W powyższym przykładzie do zapisania x wystarczy 6 bitów, natomiast do zapisania y potrzebne są 2 bity (maksymalna wartość y to 4, jednak nie ma sensu zaznaczać wystąpienia ciągu o długości 0 znaków, możemy zatem zapisywać bitowo y – 1).
Do zapisania jednego tokenu wystarczy więc 1 bajt. Współczynnik kompresji dla powyższego przykładu, obliczony wg wzoru [1], wynosi 32/44 · 100% = 72,73%. Najbardziej znanym algorytmem kompresji słownikowej, na którym bazują algorytmy wykorzystywane w programach takich, jak WinZIP, WinRAR, jest algorytm LZW (od nazwisk autorów: Lempel-Ziv-Welch).
![]() Ćwiczenie 3. Obliczamy współczynnik kompresji
Ćwiczenie 3. Obliczamy współczynnik kompresji
Za pomocą metody słownikowej dokonaj kompresji zdania: „Moją pasją są kompresje i ich komputerowe wersje”. Oblicz współczynnik kompresji.
![]() Zadania
Zadania
- Podaj przykład kompresji statystycznej niezwiązanej z komputerami.
- Na czym polega kompresja danych?
- W jakim celu kompresujemy dane? Podaj kilka przykładów.
- Wskaż na przykładzie różnice między kompresją stratną i bezstratną. Dla zainteresowanych
- Napisz w wybranym języku programowania program obliczający i wypisujący częstotliwość występowania liter języka polskiego. Zmierz tę częstotliwość na podstawie tekstu „Pana Tadeusza” Adama Mickiewicza (tekst znajdziesz w Internecie).