
Temat ten można potraktować jako temat dodatkowy, uzupełniający.
Wszystkie treści na stronie ir.migra.pl są chronione prawami autorskimi. Więcej informacji znajdziesz tutaj.
Spis treści
- Reprezentacja obrazu w komputerze
- Modele barw
- Głębokość barw
- Formaty plików grafiki bitmapowej
- Grafika wektorowa
- Grafika trójwymiarowa
- Reprezentacja dźwięku w komputerze
- Format „Wave”
- Format MP3
- Format MIDI
- Reprezentacja animacji w komputerze
1. Reprezentacja obrazu w komputerze
Reprezentacja obrazu w komputerze jest bezpośrednio związana ze sposobem działania urządzeń wyjściowych, a dokładniej monitora i drukarki. Zarówno obraz wyświetlany na ekranie monitora, jak i drukowany na drukarce, składa się z wielu małych punktów, zwanych pikselami. Każdy piksel ma swój własny, niezależny od innych kolor. Matrycę takich punktów nazywamy mapą bitową (ang. bitmap) lub rastrem. Mówimy więc o grafice bitmapowej lub rastrowej.
1.1. Modele barw
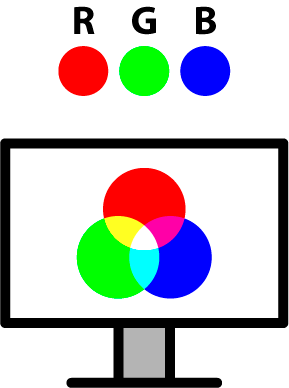
Jeżeli na ekranie komputera nie występuje żadna z wymienionych w ramce barw składowych, uzyskujemy kolor czarny. Maksymalne natężenie wszystkich składowych barw daje kolor biały. Ten model barw nazywamy modelem RGB (z ang. Red, Green, Blue). Dla człowieka wybór właściwej barwy w modelu RGB jest skomplikowany i sprowadza się do manipulowania natężeniami poszczególnych składowych. Ludziom znacznie łatwiej jest określić barwę za pomocą trzech parametrów: odcienia barwy (np. zielona, niebieska, czerwona itd.), nasycenia (nasycona ↔ pastelowa) oraz intensywności lub jasności (jasna ↔ ciemna). Taki model barw nazywamy modelem HSV (z ang. Hue, Saturation, Value) lub HSB (ang. Hue, Saturation, Brightness).
Jeszcze inny jest sposób uzyskiwania barw w druku. Tutaj pożądany kolor otrzymujemy przez zmieszanie barw: szarobłękitnej (ang. cyan), purpurowej (ang. magenta) i żółtej (ang. yellow). Teoretycznie zmieszanie tych trzech składowych w maksymalnym natężeniu powinno dać kolor czarny, jednak w praktyce, ze względu na niedoskonałość pigmentów w farbach drukarskich, uzyskany kolor jest ciemnoszary. Aby uzyskać pełną paletę barw, dodajemy czwartą składową – czarną. Ten model nazywamy modelem CMYK (z ang. Cyan, Magenta, Yellow, blacK). Ponieważ we wszystkich urządzeniach wyświetlających wykorzystuje się model RGB, a w urządzeniach drukujących – model CMYK, zwykle nie jest możliwe dokładne odwzorowanie zawartości ekranu na drukarce ani np. zeskanowanie zdjęcia przy zachowaniu wszystkich odcieni. Należy o tym pamiętać, pracując z grafiką komputerową.

1.2. Głębokość barw
W najprostszym przypadku kolor każdego piksela można przedstawić dwustanowo: piksel zapalony (kolor biały) lub piksel zgaszony (kolor czarny). Te dwa stany można zapisać za pomocą dwóch wartości: 1 i 0, a więc jednego bitu. Ten tryb (zwany często z ang. lineart) nadaje się do przedstawiania tekstów, prostych schematów itp.
Inny rodzaj obrazów to obrazy w skali szarości (ang. greyscale). Rozróżniamy tutaj stany pośrednie pomiędzy bielą a czernią – odcienie szarości. Najczęściej wszystkich możliwych odcieni jest 256, a do opisania jednego piksela potrzeba 8 bitów (1 bajt). Ten tryb nadaje się np. do pracy z czarno-białymi fotografiami. Warto zwrócić uwagę, że chociaż większość drukarek monochromatycznych potrafi wydrukować takie obrazy, to na wydruku składają się one tylko z białych lub czarnych punktów – efekt odcienia szarości uzyskuje się, stosując technikę tzw. roztrząsania (ang. dithering).
Kolejny sposób zapisu informacji o kolorze to tryb koloru indeksowanego (ang. indexed colour). W tym trybie mamy do dyspozycji ściśle określoną liczbę kolorów wybranych z większej palety barw. Na ogół liczba dostępnych kolorów jest potęgą dwójki i wynosi 16 (4 bity/piksel) lub 256 (8 bitów/piksel). Tryb ten wykorzystuje się do prostych rysunków i animacji (cliparty, przyciski na stronach WWW, banery reklamowe), nie nadaje się on natomiast do zapisu fotografii.
Zaawansowaną metodą opisu barwy punktu jest tryb tzw. prawdziwego lub pełnego koloru (ang. true colour). W tym trybie mamy do dyspozycji równocześnie ponad 16 milionów barw (dokładnie 224). Każdy piksel jest opisany przez trzy składowe: czerwoną, zieloną i niebieską, a każda składowa – przez liczbę z zakresu od 0 (brak danej składowej) do 255 (składowa w pełnym natężeniu). Jest to najdokładniejszy sposób opisu, ale jego wadą jest duża objętość obrazu w pamięci komputera. W wielu zastosowaniach (np. w języku HTML) kolor zapisujemy, podając kolejno składowe (czerwoną, zieloną i niebieską) w zapisie szesnastkowym (np. #ff0000 – to kolor czerwony, a #c0c0c0 – kolor jasnoszary).
Obecnie w wielu zastosowaniach (np. w telewizorach nowej generacji) do opisu koloru pojedynczego piksela używa się większej liczby bitów – 10, 12 lub nawet 16. Pozwala to na przedstawienie większej liczby barw i odcieni szarości. Jednym z zastosowań jest technika HDR (ang. High Dynamic Range), pozwalająca przedstawić obrazy o zakresie jasności porównywalnym do zakresu jasności widzianego przez człowieka.
![]() Ćwiczenie 1. Obliczamy, ile miejsca w pamięci komputera zajmuje obraz
Ćwiczenie 1. Obliczamy, ile miejsca w pamięci komputera zajmuje obraz
Oblicz, ile miejsca w pamięci komputera zajmie obraz o rozdzielczości FullHD (1920×1080 pikseli), zapisany w trybie dwukolorowym, w odcieniach szarości oraz w pełnym kolorze.
![]() Ćwiczenie 2. Rozróżniamy kolory HTML
Ćwiczenie 2. Rozróżniamy kolory HTML
Sprawdź, jakie to kolory: #ffffff, #ee00ee, #000000, #0000f0.
1.3. Formaty plików grafiki bitmapowej
Jakość grafiki bitmapowej jest ściśle uzależniona od liczby pikseli na obrazie – im więcej pikseli, tym lepiej. Zwiększanie liczby punktów prowadzi jednak nieuchronnie do zwiększania objętości plików graficznych. Można temu zaradzić, stosując kompresję. W grafice wykorzystuje się zarówno kompresję bezstratną (kompresja LZW w formatach GIF i TIFF), jak i stratną (w formacie JPEG). Kompresja JPEG jest bardzo efektywna i pozwala na nawet 10-krotne zmniejszenie objętości obrazu bez utraty jakości (przy większym stopniu kompresji zniekształcenia zaczynają być dostrzegalne gołym okiem). Niestety, kompresja JPEG nie nadaje się do rysunków o wyraźnych, ostrych konturach, może bowiem powodować ich rozmycie – takie rysunki lepiej zapisać w innym formacie.
Niestety, grafika bitmapowa nie zawsze jest optymalnym rozwiązaniem. Jej zasadniczą wadą jest to, że liczba punktów obrazu jest skończona, więc powiększanie rozmiarów obrazu oznacza powiększanie pikseli. Pogarsza to jakość obrazu (tzw. pikselizacja).
1.4. Grafika wektorowa
Pikselizacji, która jest wadą grafiki bitmapowej można uniknąć, zapisując obraz w postaci zbioru obiektów geometrycznych (typu: odcinek, łuk, okrąg, prostokąt, krzywa), z których każdy ma określone położenie i wielkość oraz dodatkowe atrybuty (np. grubość linii, kolor linii, kolor wypełnienia). Taki obraz poddaje się wszelkim przekształceniom geometrycznym (skalowanie, obrót) bez utraty jakości. Grafika wektorowa świetnie nadaje się do opisu clipartów, czcionek, rysunków technicznych, schematów, infografiki, ale kompletnie zawodzi w przypadku np. dzieł malarskich czy fotografii, które trudno przecież opisać geometrycznie.
Popularne formaty zapisu grafiki wektorowej to: CDR (CorelDraw), EPS (Encapsulated PostScript), WMF (Windows Meta File), SVG (format programu Inkscape, obsługiwany np. przez przeglądarki internetowe).
1.5. Grafika trójwymiarowa
W grafice trójwymiarowej, zwanej także grafiką 3D (z ang. 3-Dimensional – „trójwymiarowy”), podobnie jak w grafice wektorowej, opis obrazu jest matematyczny, zawiera jednak dodatkowo informacje o położeniu obiektów w trzecim wymiarze (głębokość). Definiowane są: położenie patrzącego (obserwatora) w przestrzeni trójwymiarowej oraz informacje o oświetleniu (liczba źródeł światła, ich kolor i natężenie). Określany jest też rodzaj powierzchni obiektów (matowe, błyszczące, przezroczyste, lustrzane) itp. Mając do dyspozycji tego typu dane, możemy odwzorować przestrzeń trójwymiarową na płaskim ekranie (wykonać rzut). Możemy również zdefiniować ruch obiektów (obrót, przesuwanie się), zaprogramować ruch obserwatora, ruch świateł itp. Ostatnią fazą jest wykonanie odpowiednich obliczeń przez komputer (w zastosowaniach profesjonalnych mogą to być dziesiątki lub setki komputerów). Ten typ grafiki jest niezwykle realistyczny, co można zaobserwować chociażby w kinie lub grach komputerowych. Niestety grafika trójwymiarowa wymaga olbrzymiej ilości obliczeń, a więc i komputera (w szczególności karty graficznej) o odpowiedniej mocy obliczeniowej.
Najbardziej znane programy do grafiki trójwymiarowej to m.in. Paint 3D, 3DStudio Max, Blender, POV-Ray, SketchUp.
2. Reprezentacja dźwięku w komputerze
2.1. Format „Wave”
Fizycznie dźwięk to fala akustyczna, której amplituda zmienia się w czasie. Zmiana ta jest płynna, w każdym momencie wielkość amplitudy może być inna. Opisanie takiej fali za pomocą wzoru matematycznego byłoby trudne, dlatego w systemach komputerowych dokonuje się digitalizacji sygnału (jego zamiany na postać cyfrową). Digitalizacja polega na pomiarze wartości amplitudy dźwięku w równych odstępach czasu (rys. 2.). Zmierzone wartości można zapisać w postaci liczbowej (patrz temat A1, „Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres podstawowy. Klasa III”). Proces ten nazywamy próbkowaniem (ang. sampling), a uzyskany w ten sposób zapis dźwięku – próbką (ang. sample). Jakość uzyskanej próbki zależy od dwóch czynników:
- częstotliwości próbkowania,
- dokładności zapisu liczbowego próbki.
Większa częstotliwość próbkowania i większa dokładność zapisu przekładają się na wyższą jakość dźwięku cyfrowego. Na przykład płyty muzyczne CD są zapisane przy użyciu następujących parametrów:
- częstotliwość próbkowania 44,1 KHz (pomiar odbywa się 44100 razy na sekundę),
- każda wartość jest zapisana na dwóch bajtach (65536 możliwych wartości). Taki format dźwięku nosi nazwę Wave (ang. wave – „fala”).
![]() Ćwiczenie 3. Obliczamy, ile miejsca w pamięci komputera zajmuje jedna sekunda dźwięku
Ćwiczenie 3. Obliczamy, ile miejsca w pamięci komputera zajmuje jedna sekunda dźwięku
1. Uruchom program Rejestrator głosu (Rejestrator dźwięku), będący standardowym elementem systemu Windows. Sprawdź, jakie parametry zapisu dźwięku umożliwili twórcy programu.
2. Oblicz, ile miejsca w pamięci komputera zajmuje jedna sekunda dźwięku zapisanego w jakości CD (pamiętaj, że dźwięk na płycie jest dźwiękiem stereo, dane są więc zapisane osobno dla lewego i prawego kanału).
2.2. Format MP3
Po wykonaniu obliczeń z ćwiczenia 3. łatwo się przekonać, że nawet krótkie fragmenty dźwięku pochłaniają olbrzymie ilości pamięci. Bez zastosowania dodatkowych zabiegów trudne byłoby więc np. przesyłanie dźwięku za pomocą sieci komputerowych, w tym Internetu.
Z pomocą przychodzą nam kompresja danych (temat A2, część III materiału edukacyjnego) oraz specyficzne właściwości ludzkiego ucha. Człowiek słyszy tylko dźwięki o częstotliwości od ok. 20 Hz do 20 KHz, przy czym dobrze słyszy wyłącznie te o częstotliwości do 5 KHz. Ponadto w przypadku, gdy nakładają się na siebie dwa dźwięki o podobnej częstotliwości, słyszymy tylko głośniejszy z nich. Matematyczny opis tych i innych właściwości ludzkiego słuchu nazywamy modelem psychoakustycznym. Bazując na takim modelu, można z próbki dźwięku usunąć niepotrzebne informacje, zmniejszając w ten sposób objętość danych (kompresja stratna). Najbardziej popularny format takiej kompresji to tzw. MPEG-1 Layer 3, czyli w skrócie MP3, pozwalający na nawet dziesięciokrotne zmniejszenie objętości pliku bez utraty słyszalnej jakości. Pozwala to np. na przesyłanie dźwięku w czasie rzeczywistym przez Internet.
![]() Ćwiczenie 4. Szukamy informacji na temat formatów kompresji stratnej dźwięku
Ćwiczenie 4. Szukamy informacji na temat formatów kompresji stratnej dźwięku
Odpowiedz na pytanie: Jakie znasz inne formaty kompresji stratnej dźwięku?
2.3. Format MIDI
Zapewne każdy widział kiedyś zapis nutowy (partyturę) utworu muzycznego. Utwór muzyczny w takim zapisie jest podzielony na głosy (instrumenty), dla każdego zaś głosu (instrumentu) zapisano w postaci nut informacje o wysokości i czasie trwania dźwięków. Dodatkowo partytura zawiera informacje o tonacji utworu, jego tempie itp. Dlaczego tych informacji nie zapisać w postaci danych cyfrowych?
Taka idea stanowi podstawę formatu MIDI (z ang. Musical Instrument Digital Interface), który jest komputerowym odpowiednikiem partytury. Specjalne programy (tzw. sekwencery) umożliwiają komponowanie muzyki w postaci nutowej, a następnie jej odgrywanie. Dodatkową zaletą formatu MIDI jest możliwość wymiany danych z elektronicznymi instrumentami muzycznymi (np. keyboardami), co pozwala m.in. na zapisywanie w pamięci komputera granej na instrumencie muzyki – w celu jej późniejszej edycji.
Pliki w formacie MIDI mają bardzo małą objętość (rzędu kilkunastu lub kilkudziesięciu KB), ale dźwięk jest ograniczony do ustalonego z góry zbioru instrumentów (nie można w ten sposób zapisać np. głosu ludzkiego).
![]() Ćwiczenie 5. Szukamy informacji na temat programów do tworzenia muzyki
Ćwiczenie 5. Szukamy informacji na temat programów do tworzenia muzyki
Znajdź w Internecie programy umożliwiające tworzenie i zapisywanie utworów muzycznych w formacie MIDI.
3. Reprezentacja animacji w komputerze
Obraz ruchomy (animowany) to ciąg pojedynczych obrazów (klatek – ang. frames) przedstawiających poszczególne fazy ruchu, które – przy wyświetlaniu z odpowiednio dużą szybkością – tworzą w naszym oku płynny obraz. Im większa liczba klatek jest wyświetlana w ciągu sekundy, tym ruch jest bardziej płynny. W europejskim standardzie telewizyjnym i wideo (zwanym PAL) wyświetla się 50 klatek na sekundę, natomiast w amerykańskim (zwanym NTSC) – ok. 60 klatek na sekundę, przy czym na przemian wyświetlane są obrazy składające się z linii parzystych i nieparzystych. Obraz taki nazywamy obrazem z przeplotem (ang. interlaced). Rozdzielczość obrazu w systemie PAL wynosi 720 x 576 pikseli, a w systemie NTSC – 720 x 480 pikseli, gdzie jeden piksel jest opisany 16 bitami informacji o kolorze. W systemie telewizji HD standardowe rozdzielczości to 1280 x 720 pikseli oraz 1920 x 1080 pikseli, przy 48, 50 lub 60 klatkach na sekundę z przeplotem albo 24, 25 lub 30 klatkach na sekundę bez przeplotu (tzw. skanowanie progresywne). Łatwo policzyć, że zapisanie w takich rozdzielczościach nawet jednej sekundy obrazu wymaga bardzo dużej objętości pamięci.
![]() Ćwiczenie 6. Obliczamy, ile miejsca w pamięci komputera zajmuje jedna sekunda dźwięku
Ćwiczenie 6. Obliczamy, ile miejsca w pamięci komputera zajmuje jedna sekunda dźwięku
Oblicz, ile pamięci zajmuje 1 sekunda obrazu wideo w systemach PAL i NTSC.
Objętość danych niezbędnych do zapisania informacji o obrazie wideo jest zbyt duża, by przetworzyć ją bez dodatkowych zabiegów. Aby móc przetwarzać, przechowywać i przesyłać dane tego rodzaju, niezbędne jest zmniejszenie ich objętości przez zastosowanie kompresji. Algorytmy kompresji obrazu wideo bazują na fakcie, że na poszczególnych klatkach zmienia się nie cały obraz, a tylko jego fragmenty (np. porusza się postać, a tło jest nieruchome). Zamiast zapamiętywać całe klatki obrazu, można zapisywać tylko informację o zmianach w stosunku do poprzedniej klatki. W ten sposób w sekwencji danych wideo wydzielone są klatki kluczowe (pamiętane w całości) oraz klatki pośrednie (pamiętane są tylko zmiany w stosunku do poprzedniej klatki). Aby dodatkowo zmniejszyć rozmiar klatek, poddaje się je różnym rodzajom kompresji stratnej, takim chociażby jak zastosowana w formacie JPEG.
Obraz wideo poddawany jest kompresji przy zapisie oraz dekompresji przy odczycie (wyświetlaniu). Kompresji i dekompresji dokonują odpowiednie moduły programowe zwane kodekami (ang. codec – COmpressor and DECompressor). Istnieje wiele kodeków o różnych zastosowaniach, z których najbardziej znane to DV (używany w cyfrowych kamerach wideo), DivX/XviD (popularny kodek filmowy do zapisu filmów) oraz H.264, H.265 i VP8 (wykorzystywane do zapisu filmów w jakości HD). Aby możliwe było odtworzenie filmu skompresowanego danym kodekiem, kodek ten powinien być zainstalowany w systemie operacyjnym. Można też skorzystać z jednego z uniwersalnych odtwarzaczy plików multimedialnych, np. programu VideoLAN (VLC).
Niezależnie od wykorzystanych kodeków informacje o obrazie wideo i dźwięku można zapisać w wielu formatach plików (tzw. kontenerach). Najbardziej popularne z nich to: AVI, FLV, MP4 MKV.
![]() Ćwiczenie 7. Sprawdzamy, jakie kodeki wykorzystano do kompresji obrazu i dźwięku
Ćwiczenie 7. Sprawdzamy, jakie kodeki wykorzystano do kompresji obrazu i dźwięku
Otwórz wybrany plik wideo w programie VLC. Sprawdź, jakie są parametry obrazu (rozdzielczość, liczba klatek na sekundę) oraz jakie kodeki wykorzystano do kompresji obrazu i dźwięku. (opcja Narzędzia/Informacje o kodeku).